


- ?dition,
- Recherche,
Partager des données de recherche qualitatives en SHS : de l’anonymisation à la diffusion des données
Pourquoi anonymiser ses données ?
L’ouverture des données, pleinement intégrée aux politiques de science ouverte, se développe dans un contexte de vigilance accrue qui concerne le traitement, l’exploitation et la conservation de données à caractère personnel.Les données qualitatives, souvent issues d’entretiens ou de notes d’enquêtes, font partie des matériaux courants en sciences sociales. Pourtant, les données qualitatives sont plus rarement ouvertes que les données quantitatives, car leur caractère individuel (parcours professionnel, lieu de vie, conditions économiques et sociales, etc.) ou sensibles (opinions politiques, religieuses, orientation sexuelle, etc.) génère davantage d’obstacles à leur ouverture.
La suppression ou la transformation des données identifiantes s’impose alors comme la solution pour ouvrir ses données de recherche sans contrevenir aux enjeux de protection de la vie privée régie par le règlement général de protection des données (RGPD).
Cette fiche explicite les bonnes pratiques à mettre en place pour ouvrir des données qualitatives. Elle clarifie les notions d’anonymisation, de pseudonymisation et fournit des méthodes illustrées par des exemples issus de données qualitatives en accès ouvert.
- Données à caractère personnel et informations identifiantes
- Le traitement à mettre en place porte sur les informations dites identifiantes. Généralement, on qualifie d’identificateurs directs les informations qui, à elles seules, permettent d’identifier immédiatement une personne. Les identificateurs indirects doivent à l’inverse être croisés pour déduire l’identité d’une personne. On peut alors distinguer :
- Les identificateurs directs sans équivoque : données génétiques, données biométriques, empreintes digitales, signature nominative, etc.
- Les identificateurs directs contextuels : prénom (il peut y avoir des homonymes), photographie (dépend de sa qualité), adresse mail (dépend de son libellé), etc.
- Les identificateurs indirects associées à une base de données : un numéro de téléphone avec un annuaire, un poste dans un établissement avec un organigramme, etc.
- Les identificateurs indirects croisés entre eux : ?ge, profession, commune de résidence, niveau d’étude, etc. Croiser toutes ces données permet de rétrécir à chaque fois le champ des possibles.
Les personnalités publiques revêtent ici un caractère particulier. En effet, certaines de leurs données dont on jugerait d’abord qu’elles sont à caractère personnel sont en fait déjà publiques du fait de leur notoriété [1].
[1] On peut penser aux personnalités exer?ant les fonctions de maire, artiste, sportif professionnel, etc. - Anonymisation et pseudonymisation : quelle différence ?
- Il existe deux processus de traitement qui permettent de protéger des données à caractère personnel : l’anonymisation et la pseudonymisation. D’un point de vue juridique, leur différence repose sur le principe de réversibilité. L’anonymisation est un processus irréversible, ce qui signifie que les données sont définitivement transformées à son issue : l’identité des personnes interrogées ne peut être reconstituée.
La pseudonymisation, à l’inverse, est réversible : la version originale des données est préservée si bien que celles-ci restent accessibles pour le chercheur ou l’équipe de recherche.
Du point de vue des chercheurs, la perte définitive du caractère identifiant des locuteurs semble peu compatible avec la production de données qualitatives sérieuses, puisque les spécificités personnelles des individus sont au c?ur des objets de recherche [2].
[2] "Si l’on s’en tient à une définition stricte de l’anonymat, l’anonymisation est non seulement impossible à mettre en ?uvre – puisqu’il faudrait "brouiller" la totalité des données personnelles qui constituent le corps même de l’entretien –, mais stérile, puisqu’elle contrevient à l’objectif d’une méthodologie qualitative et compréhensive qui vise à tisser des réseaux de signification entre les informations et/ou les éléments de discours recueillis. L’anonymisation dans une définition stricte n’est donc ni envisageable ni souhaitable.", dans Marie HUYGHE, Laurent CAILLY et Nicolas OPPENCHAIM, "Ouverture de données qualitatives à caractère personnel. Approche éthique, juridique et déontologique", in V. GINOUV?S et I. GRAS, La diffusion numérique des données en SHS Guide des bonnes pratiques éthiques et juridiques Recherche Data Gouv, Presses universitaires de Provence, 2018, p. 162. - L’anonymisation confrontée à la réalité de la recherche
- Par souci de rationalité, d’efficacité et de compromis, l’anonymisation des données de la recherche consiste à trouver un équilibre entre la conformité juridique et l’intérêt scientifique. L’idée est d’altérer assez les données à caractère personnel pour protéger les personnes concernées tout en appauvrissant le moins possible les résultats de la recherche.
Ainsi, lorsqu’il s’agit de décider à quel point il faut transformer telle ou telle donnée, il faut définir des priorités et faire preuve de bon sens. Une bonne procédure d’anonymisation s’inscrit dans une gestion raisonnable du risque : sous-estimer le risque d’identification met les individus concernés en danger, tandis que le surestimer appauvrit les données.
Un compromis peut consister à déposer les données en accès restreint dans un entrep?t de données, afin de permettre aux auteurs de contr?ler leur consultation et de limiter celle-ci à la communauté académique. Du point de vue de la science ouverte, ce genre de démarche s’inscrit pleinement dans l’équilibre exprimé par ce célèbre adage :Aussi ouvert que possible, aussi fermé que nécessaire [3]
C’est par exemple la démarche de l’entrep?t de données du Centre des données socio-politiques (CDSP), où l’accès public à des jeux de données qualitatives reste marginal et souvent limité à des usages pédagogiques [4].
[3] Voir https://openscience-ipr.eu/as-open-as-possible/
[4] Voir la collection "Bases de données pédagogiques" dans l’entrep?t Data Sciences Po : https://data.sciencespo.fr/dataverse/bddp - Les étapes de la collecte à la diffusion de données qualitatives en SHS
-
Respecter trois principes de base pour empêcher toute réidentification
Pendant la transformation de données qualitatives, mieux vaut veiller à prendre des précautions qui sont valides quelle que soit la méthode utilisée ou la profondeur du traitement [5]. En l’occurrence, il faut se prémunir contre :
- L'individualisation : un individu ne doit pas pouvoir être isolé dans le jeu de données
- La corrélation : il ne doit pas être possible de relier des ensembles de données distincts concernant un même individu
- L'inférence : de nouvelles informations sur un individu ne doivent pas pouvoir être déduite en fonction de celles déjà
Repérer les informations identifiantes
Le partage des données qualitatives requiert au préalable de relever toutes les données à masquer. Ensuite, il faut estimer du mieux possible, en fonction de leur nature et du contexte, le degré de priorité à accorder à chacune d’entre elles.
Les données dont on estime qu’elles sont des identificateurs directs doivent être altérées en premier et ne doivent faire l’objet d’aucun compromis. En revanche, parmi les identificateurs indirects, le degré d’altération dépend de votre stratégie [6].
Dans l’extrait qui suit, l’auteur a opté pour une altération poussée des données :??Actuellement, je prépare un doctorat en histoire de l’art sur (sujet de thèse). Je fais cela à (ville) avec le professeur (nom) que j’avais rencontré à (nom de ville).?Pour ma recherche actuellement, je suis en train de constituer un corpus (nature du corpus). ?
Simon DUMAS PRIMBAULT, E1, "Transcriptions de sept entretiens semi-directifs réalisés avec des usagers de Gallica au sujet de leurs pratiques informationnelles", v.2.
Les informations relatives à la préparation d’une thèse sont la plupart du temps publiques (sujet, directeur de thèse, établissement d’affiliation), mais l’auteur a choisi, dans le cadre de son étude sur l’usage de Gallica, d’occulter la quasi-totalité des éléments identifiants, en dehors de la discipline du ou de la doctorante.
Transcrire les données dans un document structuré
Les modalités de mise en forme de données qualitatives à des fins d’exploitation, de partage et de réutilisation peuvent répondre à une grande variété de méthodes.
L’un des formats envisageables est le tableur car il confère une structure visuelle claire et s’avère facile à prendre en main.
- Exemple 1
-
Les jeux de données qualitatives en open access sont parfois présentés sous cette forme, comme en témoigne le premier exemple ci-dessous, où la mise en forme des entretiens a été retravaillée de manière à classifier les réponses par thématique, ce qui permet à tout utilisateur potentiel de cibler rapidement les extraits pertinents.
Extrait de la transcription contenue dans le fichier "extraits_entretiens", dans le paquet ? dataverse_files.zip ? issu de Université Paris-Saclay, Les entretiens qualitatifs de l'enquête "Les données de la recherche à l'université Paris-Saclay, panorama et perspectives", v. 1.
- Exemple 2
-
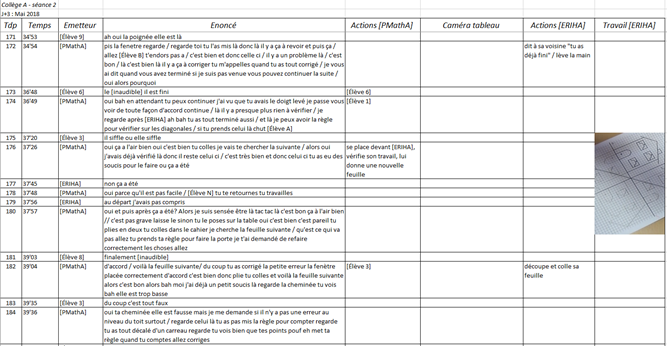
Dans le deuxième exemple ci-dessous, relatif à une enquête de terrain sur l’enseignement des mathématiques auprès d’élèves en situation de handicap, l’auteur a choisi de retranscrire l’ensemble des échanges entre les élèves et le professeur tout en incluant l’horodatage dans un tableur :
Extrait de la transcription de l’enregistrement "Collège A – Séance 2", dans le paquet "03_J3_seance_2.zip" issu de Frédéric DUPR?, "Pratiques inclusives en mathématiques en ULIS collège : présentation du jeu de données", Recherche Data Gouv, v. 1, 2023.
Les entretiens peuvent également être transcrits dans un document texte. Cette méthode est moins chronophage pour l’auteur du jeu de données car elle ne requiert pas de traitement particulier, en dehors des précautions d’usage en matière de données personnelles. En contrepartie, elle demande aux utilisateurs de s’immerger dans l’intégralité du texte afin d’en déterminer les éléments pertinents. L’exemple ci-dessous fournit une illustration de ce choix :
Extrait de la transcription de l’entretien n° 5 issu de Shirish RAIBAGKAR "Publish or perish — Interviews", v. 1, 2022.
Le recours à des logiciels de retranscription automatique conduit par ailleurs certains chercheurs à fournir le fichier d’export brut issu de l’outil utilisé, comme le propose l’exemple ci-dessous :
Extrait de la transcription de l’enregistrement ? E1 ?, issu de Simon DUMAS PRIMBAULT, Ibid.
? Résultat sur la page web : https://www.nakala.fr/10.34847/nkl.320eu55q#38c4ee7f219750570215b540f557df9a611c05f6
Le développement des outils de transcription automatique est en plein essor. Du c?té des solutions open source, Whisper fait partie des outils leaders du marché (via les applications Buzz ou Vibe). Dans la recherche, l’outil de transcription open source Transana est aussi largement adopté. Développé à l’ENS de Lyon, l’outil TransICOR entreprend quant à lui d’adapter le logiciel open source Transcriber à la convention de transcription ICOR approuvée par le CNRS.
Les procédés d’altération des données, dont la CNIL recommande qu’ils soient validés par le délégué à la protection des données peuvent se décliner de plusieurs manières [7].
Appliquer une méthode de transformation efficace et cohérente
L’une des méthodes de transformation les plus courantes consiste à attribuer un identifiant générique à chaque donnée sensible. Il peut s’agir d’une lettre ou d’un numéro, par exemple. Cette méthode simple apporte un indice contextuel, comme une information sur le statut des personnes. Par exemple :
"Il s’agissait tout d’abord de supprimer les identifiants directs (les noms et prénoms). Ceux-ci ont été remplacés par des codes écrits entre crochets [?lèves A]." [8]
Toutefois, cette solution se heurte à certaines recherches dotées d’une dimension sociale importante. Les données qui s’intéressent à un échantillon de population caractérisé par son engagement politique perdent toute possibilité de réutilisation en étant décontextualisées :
"Une fois ouvertes, une partie des pièces restent malaisées à appréhender. Celles rééditées, en particulier, soit la plupart des notes d’observation et des transcriptions d’entretiens, comportent des passages exigeant le gout des rébus pour être utilisées, du fait des formules codées de la pseudonymisation, par endroits envahissantes, selon l’exemple qui suit (note du 16 juillet 1997).
? ce moment-là alors que les jeunes juifs sont déjà partis, ((anonym: initiale8)) qui s’était éloigné et va arriver et dire d’une voix audible sur le ton de la plaisanterie "mort aux juifs", mouvements d’exaspération de ((anonym: initiale2)) et ((anonym: initiale1)), au point que ((anonym: initiale1)) va quitter le groupe pour une partie de la journée, ((anonym: initiale8)) essaiera sans succès de le retrouver, quand ((anonym: initiale1)) reviendra, une heure plus tard, ((anonym: initiale8)) s’excusera, appuyé par le ((anonym: cdsp_bq_s11_col_entr_indv_trans_en01_FR)), ((anonym: initiale1)) dira que c’est fini, qu’il fait beau, qu’il ne veut plus en entendre parler.
Ici, la dé-identification totale est privilégiée, rendant impossible toute vérification par d’autres chercheurs "afin de tester le bien-fondé des résultats", qui nécessiterait de faire conna?tre le nom des lieux, des institutions, d’une partie au moins des personnes, de fa?on à ce qu’elles puissent être contactées." [9]
Autre option applicable aux groupes culturels particuliers : le choix d’un alias partageant une particularité avec le nom auquel il renvoie afin de conserver une part des références implicites [10] :
"Nous cherchons à éviter au maximum les numérotations (comme PAT1, PAT2, ou CLI1, CLI2, par exemple pour ? patient 1, patient 2… ? ou ? client 1, client 2 ?) et à choisir plut?t des prénoms et noms, qui nous semblent garder une forme d’humanité aux participants." [11]
Le chercheur doit ainsi attribuer un alias à chaque donnée sensible, l’idée étant d’attribuer des alias cohérents et de conserver si possible une information contextuelle pertinente — préférer "?lève" à "Enfant" dans le cas d’une recherche en milieu scolaire, par exemple.
Par ailleurs, il existe déjà des procédures qui font l’objet d’une application plus large : c’est le cas de la convention ICOR, développée par le laboratoire ICAR du CNRS, qui a vocation à servir de guide aux chercheurs fran?ais pour l’anonymisation des transcriptions d’enregistrements audio [12].
Déposer les données dans un entrep?t de confiance
Une fois que vos données sont prêtes à être diffusées, vous pouvez les déposer dans un entrep?t de confiance. Les entrep?ts de confiance sont des bases de données publiques qui offrent de la visibilité à vos ressources. Vos jeux de données participent ainsi à la science ouverte [13].
L’entrep?t Recherche Data Gouv fait figure de référence nationale [14]. Cependant, il peut être pertinent de publier vos données dans un entrep?t spécialisé dans votre discipline [15] et disposant d’un service d’accompagnement sur les données qualitatives (CDSP en sciences politiques, UK Data Service, etc.)
Une large gamme d’outils s’est développée pour systématiser l’occultation des éléments identifiants. Or, plus le cadre de l’entretien est rigide, plus il est facile de déterminer les données sensibles puisque leurs occurrences apparaissent systématiquement aux mêmes endroits. C’est pourquoi les outils d’anonymisation automatique s’avèrent pertinents pour les entretiens de type directif. Parmi les outils open source et plébiscités en France, mentionnons ARX et Amnesia [16].
Les outils d’anonymisation automatique
En revanche, les outils d’anonymisation sont inaptes à produire un jugement complexe sur le degré d’altération à appliquer à chaque donnée. En ce qui concerne les entretiens semi-directifs, les outils d’anonymisation procurent un avantage moindre, car il faut déployer un processus de post-correction qui limite leur utilité.
Dans des cas exceptionnels, lorsque l’infrastructure le permet et que le volume de données à traiter le requiert, il est possible d’avoir recours à un algorithme d’apprentissage automatique pour anonymiser des données qualitatives. C’est le cas à la Cour de Cassation où un modèle d’IA a été développé pour anonymiser automatiquement les décisions de justice. Cela mobilise beaucoup de ressources humaines et matérielles, puisqu’il faut piloter l’entrainement de l’IA, l’alimenter constamment en données de qualité et entretenir l’infrastructure informatique nécessaire à son bon fonctionnement [17].
[5] Christiane F?RAL-SCHUHL, "Anonymiser les données ne suffit pas à s'exonérer du RGPD", CIO, 29 novembre 2023.
[6] La participation d’un individu à un événement public peut a priori être jugée comme un identificateur indirect. Il n’est pas impossible de retrouver ladite personne dans les archives de la presse si l’événement a bénéficié d’une couverture médiatique. La sensibilité de l’information peut aussi être accrue si l’événement revêt une connotation politique, syndicale, religieuse, etc. Il faut cependant veiller, là encore, à garder du bon sens : si ce type d’événement est justement l’objet de la recherche, difficile d’effacer tout ce qui le concerne.
[7] CNIL, Recherche scientifique (hors santé) : enjeux et avantages de l’anonymisation et de la pseudonymisation, 2022. Le DPD (Délégué à la protection des données), ou DPO (Data Protection Officer), est une personne chargée de la protection des données personnelles au sein d’une structure. Dans notre cas, il s’agit de la ou le juriste responsable de la conformité des données diffusées au RGPD. Voir https://www.cnil.fr/fr/definition/delegue-la-protection-des-donnees-dpo.
[8] Frédéric DUPR?, "Pratiques inclusives en mathématiques en ULIS collège : présentation du jeu de données", Recherche Data Gouv, v. 1, 2023.
[9] Daniel BIZEUL, "Faut-il tout dévoiler d’une enquête au Front national ? Réflexions sur le partage des données et le devoir éthique en sociologie", Bulletin de Méthodologie Sociologique, vol. 150, n° 1, p. 70-105.
[10] Cependant, cette pratique expose à toute sorte de biais quant à la valeur culturelle et étymologique du prénom. Elle peut aussi compromettre l’identité d’une personne ayant un prénom qui se démarque du reste du groupe. Voir : "la connotation d’un nom (par exemple italien) risque de permettre l’identification du participant, si par hasard il n’y a qu’un italien dans l’enregistrement", dans Véronique TRAVERSO, "Anonymisation, pseudonymisation, consentement. Réflexions à partir d’expériences de collectes de données vidéo sur le terrain", Le droit et l’éthique : qu’est-ce qui change dans les pratiques de terrain ?, Bulletin de l’AFAS, n°48, 2022, p. 26-51.
[11] Véronique TRAVERSO, Ibid.
[12] Voir https://icar.cnrs.fr/ecole_thematique/tranal_i/documents/Mosaic/ICAR_Conventions_ICOR.pdf.
[13] Pour en apprendre plus sur les entrep?ts de confiance, voir Frédéric DE LAMOTTE, Véronique STOLL et alii, Sélectionner un entrep?t thématique de confiance pour le dép?t de données : méthodologie et analyse de l'offre existante, Comité pour la Science Ouverte. 2024.
[14] L’entrep?t de Recherche Data Gouv : https://entrepot.recherche.data.gouv.fr/.
[15] Les entrep?ts de confiance disciplinaires sont recensés ici : https://recherche.data.gouv.fr/fr/entrepots.
[16] ARX : https://arx.deidentifier.org/ ; Amnesia : https://amnesia.openaire.eu/.
[17] Voir à propos Camille GIRARD-CHANUDET, "Le travail de l’Intelligence Artificielle : concevoir et entra?ner un outil de pseudonymisation automatique à la Cour de Cassation", Technologies numériques et apprentissages, 2023.

Ressources
Entrep?ts accueillant des données qualitatives :- L’entrep?t de données de Sciences Po : https://data.sciencespo.fr/dataverse/cdsp. Tout chercheur peut y déposer ses données, sans être affilié à Sciences Po.
- L’entrep?t de l’UK Data Service : https://ukdataservice.ac.uk/find-data/browse/
- L’entrep?t Qualitative Data Repository (Université de Syracuse) : https://qdr.syr.edu/
- L’entrep?t du Consortium interuniversitaire pour la recherche politique et sociale (Université du Michigan) : https://www.openicpsr.org/openicpsr/
- L’entrep?t de la plateforme Recherche Data Gouv : https://entrepot.recherche.data.gouv.fr/